Пересечение точек монтирования в маршрутах поиска имен файлов
Давайте повторно рассмотрим поведение алгоритмов namei и iget в случаях, когда маршрут поиска файлов проходит через точку монтирования. Точку монтирования можно пересечь двумя способами: из файловой системы, где производится монтирование, в файловую систему, которая монтируется (в направлении от глобального корня к листу), и в обратном направлении. Эти способы иллюстрирует следующая последовательность команд shell'а. mount /dev/dsk1 /usr cd /usr/src/uts cd ../../..
По команде mount после выполнения некоторых логических проверок запускается системная функция mount, которая монтирует файловую систему в дисковом разделе с именем "/dev/dsk1" под управлением каталога "/usr". Первая из команд cd (сменить каталог) побуждает командный процессор shell вызвать системную функцию chdir, выполняя которую, ядро анализирует имя пути поиска, пересекающего точку монтирования в "/usr". Вторая из команд cd приводит к тому, что ядро анализирует имя пути поиска и пересекает точку монтирования в третьей компоненте ".." имени.
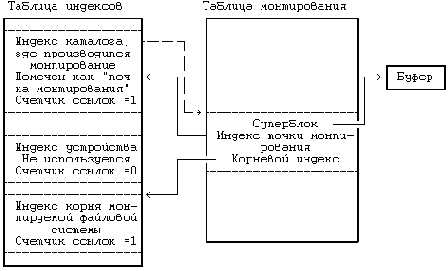
Рисунок 5.24. Структуры данных после монтирования
Для случая пересечения точки монтирования в направлении из файловой системы, где производится монтирование, в файловую систему, которая монтируется, рассмотрим модификацию алгоритма iget (), которая идентична версии алгоритма, приведенной на , почти во всем, за исключением того, что в данной модификации производится проверка, является ли индекс индексом точки монтирования. Если индекс имеет соответствующую пометку, ядро соглашается, что это индекс точки монтирования. Оно обнаруживает в таблице монтирования запись с указанным индексом точки монтирования и запоминает номер устройства монтируемой файловой системы. Затем, используя номер устройства и номер индекса корня, общего для всех файловых систем, ядро обращается к индексу корня монтируемого устройства и возвращает при выходе из функции этот индекс. В первом примере смены каталога ядро обращается к индексу каталога "/usr" из файловой системы, в которой производится монтирование, обнаруживает, что этот индекс имеет пометку "точка монтирования", находит в таблице монтирования индекс корня монтируемой файловой системы и обращается к этому индексу.
|
алгоритм iget входная информация: номер индекса в файловой системе выходная информация: заблокированный индекс { выполнить { если (индекс в индексном кеше) { если (индекс заблокирован) { приостановиться (до освобождения индекса); продолжить; /* цикл с условием продолжения */ } /* специальная обработка для точек монтирования */ если (индекс является индексом точки монтирования) { найти запись в таблице монтирования для точки мон- тирования; получить новый номер файловой системы из таблицы монтирования; использовать номер индекса корня для просмотра; продолжить; /* продолжение цикла */ } если (индекс в списке свободных индексов) убрать из списка свободных индексов; увеличить счетчик ссылок для индекса; | возвратить (индекс); } /* индекс отсутствует в индексном кеше */ убрать новый индекс из списка свободных индексов; сбросить номер индекса и файловой системы; убрать индекс из старой хеш-очереди, поместить в новую; считать индекс с диска (алгоритм bread); инициализировать индекс (например, установив счетчик ссылок в 1); возвратить (индекс); } } |
Для второго случая пересечения точки монтирования в направлении из файловой системы, которая монтируется, в файловую систему, где выполняется монтирование, рассмотрим модификацию алгоритма namei (). Она похожа на версию алгоритма, приведенную на . Однако, после обнаружения в каталоге номера индекса для данной компоненты пути поиска ядро проверяет, не указывает ли номер индекса на то, что это корневой индекс файловой системы. Если это так и если текущий рабочий индекс так же является корневым, а компонента пути поиска, в свою очередь, имеет имя "..", ядро идентифицирует индекс как точку монтирования. Оно находит в таблице монтирования запись, номер устройства в которой совпадает с номером устройства для последнего из найденных индексов, получает индекс для каталога, в котором производится монтирование, и продолжает поиск компоненты с именем "..", используя только что полученный индекс в качестве рабочего. В корне файловой системы, тем не менее, корневым каталогом является ".."
|
алгоритм namei /* превращение имени пути поиска в индекс */ входная информация: имя пути поиска выходная информация: заблокированный индекс { если (путь поиска берет начало с корня) рабочий индекс = индексу корня (алгоритм iget); в противном случае рабочий индекс = индексу текущего каталога (алгоритм iget); выполнить (пока путь поиска не кончился) { считать следующую компоненту имени пути поиска; проверить соответствие рабочего индекса каталогу и права доступа; если (рабочий индекс соответствует корню и компо- нента имени "..") продолжить; /* цикл с условием продолжения */ поиск компоненты: считать каталог (рабочий индекс), повторяя алго- ритмы bmap, bread и brelse; если (компонента соответствует записи в каталоге (рабочем индексе)) { получить номер индекса для совпавшей компонен- ты; если (найденный индекс является индексом кор- ня и рабочий индекс является индексом корня и имя компоненты "..") | { /* пересечение точки монтирования */ получить запись в таблице монтирования для рабочего индекса; освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу точки монтирования; заблокировать индекс точки монтирования; увеличить значение счетчика ссылок на рабо- чий индекс; перейти к поиску компоненты (для ".."); } освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу с новым номером (алгоритм iget); } в противном случае /* компонента отсутствует в каталоге */ возвратить (нет индекса); } возвратить (рабочий индекс); } |
В вышеприведенном примере (cd "../../..") предполагается, что в начале процесс имеет текущий каталог с именем "/usr/src/uts". Когда имя пути поиска подвергается анализу в алгоритме namei, начальным рабочим индексом является индекс текущего каталога. Ядро меняет текущий рабочий индекс на индекс каталога с именем "/usr/src" в результате расшифровки первой компоненты ".." в имени пути поиска. Затем ядро анализирует вторую компоненту ".." в имени пути поиска, находит корневой индекс смонтированной (перед этим) файловой системы - индекс каталога "usr" - и делает его рабочим индексом при анализе имени с помощью алгоритма namei. Наконец, оно расшифровывает третью компоненту ".." в имени пути поиска. Ядро обнаруживает, что номер индекса для ".." совпадает с номером корневого индекса, рабочим индексом является корневой индекс, а ".." является текущей компонентой имени пути поиска. Ядро находит запись в таблице монтирования, соответствующую точке монтирования "usr", освобождает текущий рабочий индекс (корень файловой системы, смонтированной в каталоге "usr") и назначает индекс точки монтирования (каталога "usr" в корневой файловой системе) в качестве нового рабочего индекса. Затем оно просматривает записи в каталоге точки монтирования "/usr" в поисках имени ".." и находит номер индекса для корня файловой системы ("/"). После этого системная функция chdir завершается как обычно, вызывающий процесс не обращает внимания на тот факт, что он пересек точку монтирования.